The Polyglot Model Sharing framework offers a secure environment to manage the storage of ML models and datasets, addressing four main objectives: i) enabling the traceability of assets, ii) guaranteeing their immutability, iii) ensuring the reproducibility of trained ML models, and iv) enabling a platform-independent runtime ML model representation, based on ONNX, that enables a wider range of compatible hardware for inference purposes. The framework offers a transparent data integrity mechanism, leveraging a Blockchain-based approach for storing uniquely identifying metadata of assets. This framework offers a useful feature set for applications that require the management of ML models that involve sensitive information. Additionally, due to the integration into the IoT-NGIN ML as a Service (MLaaS) platform, the framework is especially suited for IoT applications. The Model Sharing framework adopts a microservices-based design, with distinct, single purpose services, namely the Model Sharing, the Model Zero Knowledge Verification, ZKV (Blockchain metadata store), the Model Training and the Model Translation services (see Figure 1). This design was taken in concordance to another key architectural choice: offering a Cloud native solution, integrated into MLaaS, with a strong focus on DevOps, CI/CD and containerization.
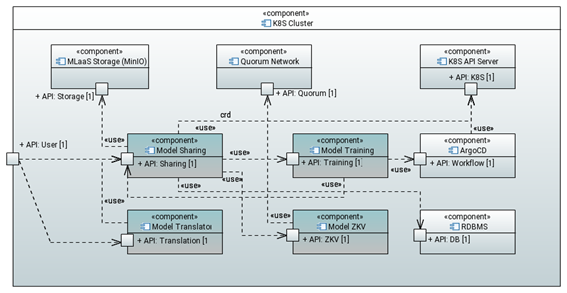
The Model Sharing service provides an interface for i) registering datasets into the MLaaS storage, ii) registering ML models, scheduling their training, and uploading the resulting trained models into the storage and iii) retrieving assets (i.e., datasets and trained models) from the storage. When processing assets, it stores their relevant metadata in the blockchain ledger, mediated by the ZKV service. Thanks to this metadata, and by exclusively overseeing the training phase of the models in a controlled environment, it can guarantee the replicability of the trained models, and ensured that their training results were achieved only with the registered inputs. Additionally, this metadata allows for guaranteeing the integrity of all stored assets.
The Blockchain service provides an interface for creating, retrieving, and interacting with smart contracts in the EVM (Ethereum Virtual Machine) ledger (i.e., ConsenSys Quorum). These smart contracts are deployed into the ledger for the assets registered in the platform. For each asset type, there exists a smart contract definition, specified with Solidity, that describes the metadata and the read-only methods available for interacting with the contract. The Model Training service offers a controlled environment for the training of ML models, aiming to guarantee the reproducibility and immutability of the resulting trained ones. Models are trained, given their associated train and test datasets. A training job is a scheduled execution of a container that encloses the model definition and training instructions. Therefore, upon model registration, a training container image, stored in a container registry of choice, must be provided. After training, the resulting trained model is automatically registered in the MLaaS storage, where is available to the user, and the rest of the platform’s services. Training jobs are executed in the MLaaS Kubernetes Edge cluster, leveraging Argo Workflows.
The Model Translation service transcompiles registered ML models into the Open Neural Network Exchange (ONNX) format upon training, offering an execution compatibility layer for models stored in the MLaaS platform. In this way, model developers can implement their ML models in their backend of choice (i.e., TensorFlow, PyTorch, etc.), while taking advantage of any particular hardware (e.g. CUDA, ROCm…) compatible with ONNX runtime.
A common user’s interaction with the Model Sharing platform is described in the following process (see Fig 2):
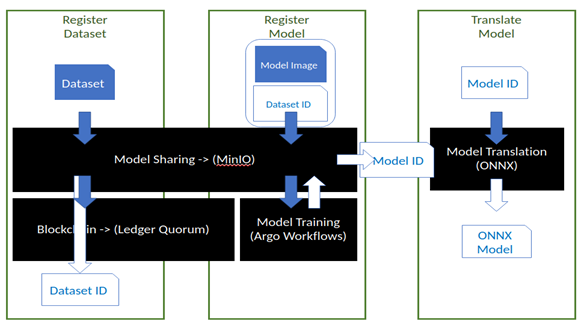
1. The user registers a dataset in the MLaaS storage, obtaining a UUID for further reference,
2. The user registers a ML model architecture in the MLaaS storage, referencing the registered dataset and a training container image. During the process, a smart contract, enclosing dataset and model metadata, is created in the Blockchain ledger. A model UUID is returned for further reference,
3. The user waits for model training completion. The user can inquire the platform for the training status,
4. Upon completion, the user retrieves the trained model and its associated contract metadata with the given UUID,
5. (Optionally) The user requests to translate the model into ONNX format, obtaining its UUID.
Model Sharing code is available at the IoT-NGIN Gitlab repository [1]. Further technical details are available in [2].
References
[1] Polyglot Model Sharing platform repository,
https://gitlab.com/h2020-iot-ngin/enhancing_iot_intelligence/t3_4/ml-model-sharing.
[2] D3.4 ML Model Sharing and Transfer learning implementation 2023.
https://iot-ngin.eu/wp-content/uploads/2023/05/IoT-NGIN_D3.4_v1.0_pending_EC_approval.pdf.