Reinforcement Learning (RL) is a machine learning discipline centered on the learning of optimal behavioral policies for decision making of a group of agents interacting in a common environment, leading to a maximization of a cumulative reward (i.e., expert-defined performance metric). In the context of control systems, the learned policy allows for the deployment of deterministic or stochastic control logic/instructions for agents interacting in the end system, such as, e.g., optimizing the grid power generation, by allowing EV charging stations to autonomously adjust their charging rate depending on the current state of the grid and the attached vehicle’s battery.
The main advantage of reinforcement learning is that it offers a set of algorithms that can learn independently, from their interactions with the environment, with a great deal of flexibility, in terms of the acquisition and usage of their experience, thus allowing its implementation in a wide range of environments, in both physical and simulated systems.
In the context of IoT-NGIN, we have developed a RL-based optimization model for the Smart Energy Living Lab (LL) and the use case “Move from Reacting to Acting in Smart Grid Monitoring”, with the purpose of optimizing and controlling the electrical network. In this scenario, a number of clusters of domestic and industrial consumers are connected to the network. The optimization objective is to compute a daily optimal consumption profile for each cluster that maximizes the network SSR (self-sufficiency ratio) and SCR (self-consumption ratio).
For learning the model, the optimization model does not interact directly with the electrical network, but with a network simulator, based on Pandapower, that leverages the Flow PYPOWER solver. The optimizer iterates over a number of episodes with a fixed number of steps, proposing, at each one, a slightly different cluster consumption profile. For each step, the simulator is fed with the new cluster profiles and computes the new network state, returning the SSR and SCR ratios, from where a new reward is obtained. Next, the optimization model, leveraging the RL Tensorforce framework, uses this reward, by adopting the Proximal Policy Gradient algorithm, to compute the optimal policy that relates the optimal action, which maximizes the reward, with the network state. By learning this policy, the optimization model can infer the optimal daily demand profile for different clusters.
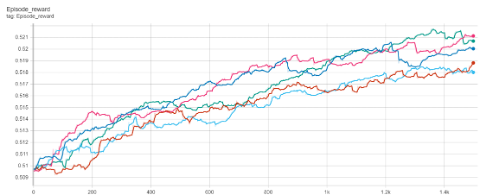
In the next figure, we can see the reward growth during the learning process in 5 episodes. As long as the optimization model explores possible consumption profiles and explodes them, learns a better policy to increase the reward.
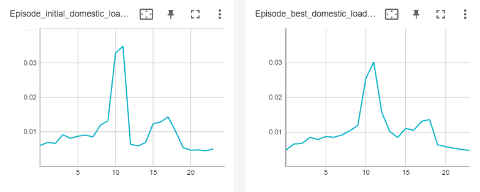
In the next figure, an example of the daily consumption profile for one cluster (on the left) and the optimal one (on the right)isdisplayed. Then, by adopting these daily consumption profiles, domestic and industrial clusters of consumers can optimize the network state.
Future experimentation on this optimization model will be conducted in the last period of the IoT-NGIN project. Additional details on this optimization model are reported in D3.3[1], D3.4[2], and details of the experimentation with the UC9 electric network in D7.3[3].
References
[2] D3.4 ML Model Sharing and Transfer learning implementation. 2023. To be published.
[2] D7.3 IoT-NGIN Living Labs use cases intermediate results. 2023. To be published.