Kubeflow is an extraordinary framework essentially allowing the emergence of MLOps or ML as a Service (MLaaS) modalities. It is readily integrated into the overall concept, context and operations of Kubernetes, rendering a perfect match for ML engineers that need to have their ML pipelines scaled at cloud level. But what happens in the context of hybrid clouds, when a graphics card is attached to a server not directly participating in a Kubernetes deployment?
Deep Learning models can be trained faster by simply running all operations at the same time instead of one after the other. GPUs are optimized for training artificial intelligence and deep learning models as they can process multiple computations simultaneously.
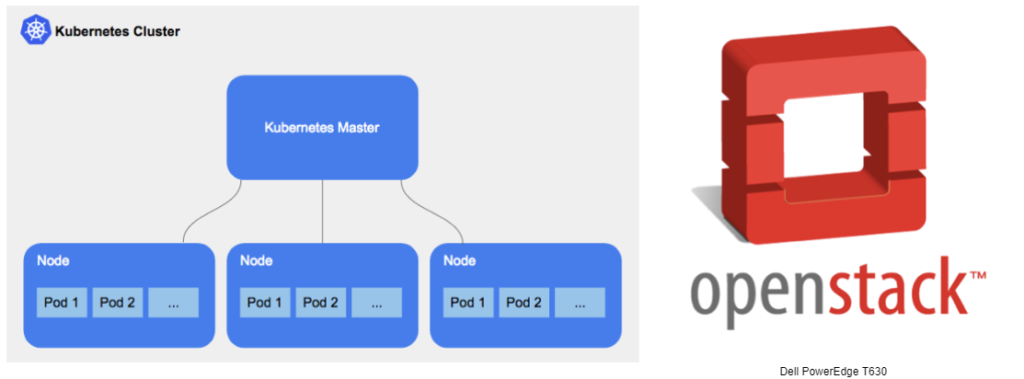
Synelixis’s mini-cloud infrastructure consists of an on-premises bare-metal Kubernetes cluster comprising multiple nodes accompanied by a disjoint OpenStack installation hosted on a single server (yes, VMs are really needed even nowadays ?). In the context of the IoT-NGIN project, we faced the need to introduce a new Kubernetes node with specialized hardware allowing Data Scientists and ML Engineers run workflows upon (effectively implementing MLaaS). Reading the documentation of Kubeflow & Kubernetes, everything seemed to be well thought of and straightforward, except for one thing; the GPU would need to be attached to a server-part of the Kubernetes cluster. In our case, however, this was not the case; the GPU was attached to the OpenStack server and could not be relocated. Consequently, we had to create a VM inside the OpenStack environment, with the GPU attached, then donate this VM to our hungry Kubernetes installation.
If you are interested in experimenting GPU passthrough in OpenStack, you can find a complete guide here.